Airbnb 的这篇论文《Real-time Personalization using Embeddings for Search Ranking at Airbnb》拿了KDD 2018 的best paper,初次看到这篇文章还是觉得很吃惊的,这么简单地一篇文章也能拿best paper。但细看之后觉得还是有不少工程上可以借鉴学习的地方。在介绍这篇文章之后先讨论一下如何用Word2vec在推荐中做Item Embeddings。
Embedding 在airbnb房源排序中的应用 (KDD2018 best paper)
Airbnb 的这篇论文《Real-time Personalization using Embeddings for Search Ranking at Airbnb》拿了KDD 2018 的best paper,初次看到这篇文章还是觉得很吃惊的,这么简单地一篇文章也能拿best paper。但细看之后觉得还是有不少工程上可以借鉴学习的地方。在介绍这篇文章之后先讨论一下如何用Word2vec在推荐中做Item Embeddings。
Word2vec 用于Item Embeddings
Word2vec 用于做词向量相信大家都比较熟悉了,研究生阶段我利用Word2vec的变形在双语词嵌入上做了一些尝试。工作之后才开始接触推荐系统,知道了有人利用Word2vec来做 Item Embeddings,放到item向量学习当然也可以说Node2vec或者 Graph Embeddings。开始我是有点质疑这样做的有效性,Word2vec 能用无监督的方式得到词向量,主要在于语言是有”结构性”的,是有“规律可循”的。例如“吃饭“总是在一起出现,或者说”吃面“,”吃肉“。就是因为有这样的规律,所以才能用word2vec训练语言模型下(也可以参考词向量的分布式假设)。但是在推荐中有这样的规律吗?从统计的角度上说,看了某个item1会经常去看另外某个item2。答案当然是存在,这是item-based CF的基本思路。所以Word2vec做ICF类召回还是很有效的。
推荐系统中,Word2vec以及它变种方法用于召回越来越常见了,很多人也夸张的说:万物皆可 Embedding,基本思路都是利用用户的点击历史看作一个”句子”,但是慢慢地在我心中有个疑问,为什么在做推荐的时候没有人想到使用负样本呢?因为用word2vec 学习item 向量时,利用上下文预测中心的item,并且选取一些负样本训练,模型其实认为点了item1就不会点它的负样本item1_neg了。(当然这里也必须选取一些负样本,如果没有负样本这里最终优化到每个item embedding都相等且norm=1,就能使得word2vec的交叉熵loss为0了。)既然在推荐系统的中有负样本,为啥不能利用到word2vec 中训练呢?在nlp中由于是无监督学习,所以只能随机的选取一些其它词来作为负样本。推荐系统与自然语言存在的差异是,我们能搜集到负样本,也应该加以利用。一方面随机选取负样本有概率落在正样本上,另一方面,这样的负样本不是更加置信吗,也更加具有”区分度“。我解释一下这里的“区分度”,如果用户喜欢看了一个”Dota游戏“的视频,这个时候负采样一个”娱乐“视频是完全没有问题的吧,但是这个视频上下文中还有一个”CS游戏“的视频我也没看,(这在推荐系统中常见,因为推荐系统会通过用的兴趣”游戏“召回这些视频)这样如果我选”CS游戏“的视频作为负样本是不是比”娱乐“的更好呢,因为我就是不喜欢CS而喜欢Dota,这样训练的Embeddings更加具有区分度。
上述这个问题一直是我的疑问,当然还没有时间去验证,结果看到这篇文章,完全解决了我之前的疑惑。这篇文章从这些方面说明了很多问题,并且结合了很多在Airbnb场景下的工程问题,仍然值得仔细研究。
Airbnb 中的 Embedding
Listing Embeddings
首先指明一下这里的Listing 就是推荐系统中的item。
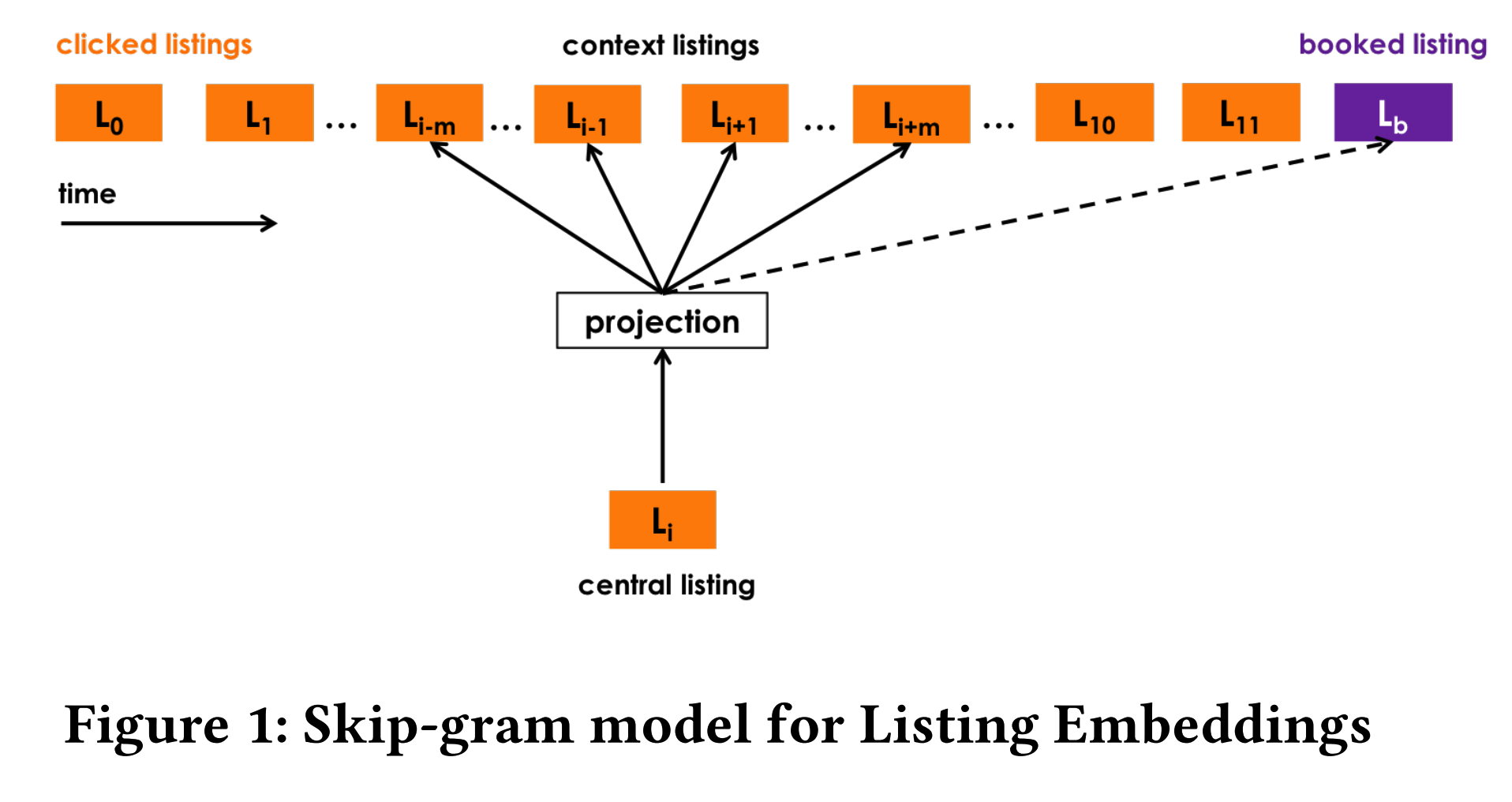
Airbnb与其他得到embedding 的方式类似,利用用的点击历史,然后上下文预测的方式训练listing embedding。
公式如下:
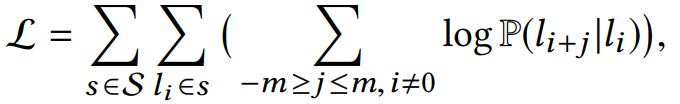
利用Skip-Gram + 负采样的方式训练上述公式,$\text{v}_l$ 是listing 的表示向量,$\text{v}_c’$是网络参数,$D_n$是负采样的样本集合。
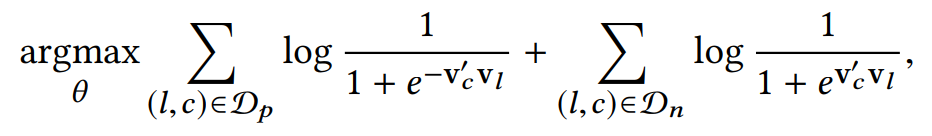
当然Airbnb不仅仅是这样做,因为有些房子不仅是用户点击过,而且是用户booked的,这里只有一个listing。也就是说在airbnb的场景中,用户看了很多房源之后最后booked了一个房源。既然是这样,airbnb希望充分利用起这样的监督信息。如Figure1,中心的listing不仅去预测它的上下文还去预测一个booked listing。这是一个global context,并且在这个序列中一直是不变的。所以它的优化目标添加了一项:
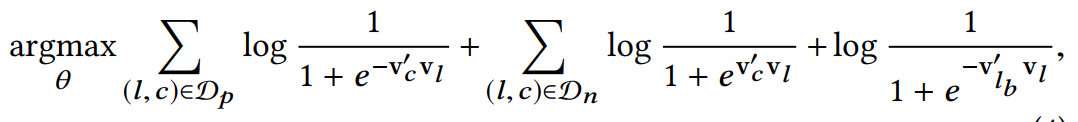
值得注意的是这里使用的参数$v_{l_b}’$与上述的$v_c’$不一样,这其实可以看作是两个不同的task,一个只是在学习中心listing与周围listing的关系,而另一个task想学习的是这一串序列所有的listing与最后的booked linsting有另外一种关系,很显然这是不一样的。另外$v_{l_b}$这里的参数量还是挺大的,是看了l然后最后选了b的所有集合大小。
这样当然还不够,为了学习更强的差异性,也就是用户会看某个房源,但不会看相同市场的其它房源,注意之前负采样是所有里面随机,而这里是选用相同的市场的其它的房源。当然这两种关系仍然是不同的,所以添加一项负采样,并且参数都不一样,如下:
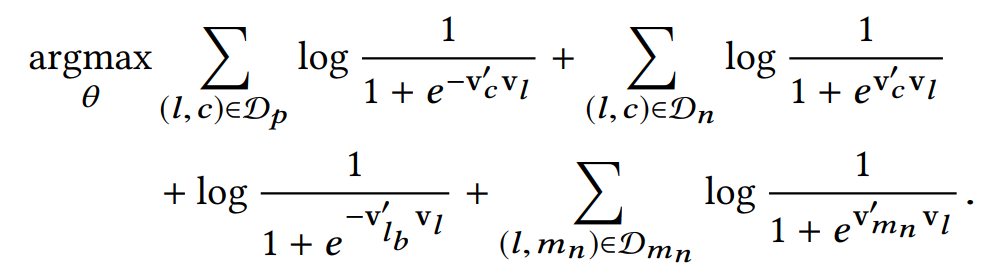
最后总结这个优化目标:
- $v_l$ 是中心房源的向量,$v’$都表示网络参数
- $D_p$ 是房源对(l,c)集合,l,c在都在一个窗口内。
- $D_n$ 是房源对(l,c)的负采样集合。
- $l_b$ 是用户看过这一系列房源最终预定的房源。一个序列只有一个。
- $D_{m_n}$是与$l$同一个市场的负采样集合。
$v_{m_n}’$是参数量大小就是每个市场下房源的集合,如果每个房源只属于一个市场,那么它就和房源字典$V$大小相同。
基于embedding 的相似房源推荐
有了每个房源的embedding 表示之后,之后可以将它利用在i2i的召回上,简单上来说就是通过用户的点击历史来推荐与这些房源相似的房源,这个相似度是通过向量的距离来计算的。
值得一提的是,Airbnb有两点比较特别
- 1.分市场找到最相似的房源
- 2.不仅利用了点击历史$H_c$,而且利用未点击的记录 $H_s$,
所以它定义了两个相似:
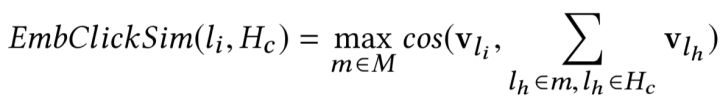
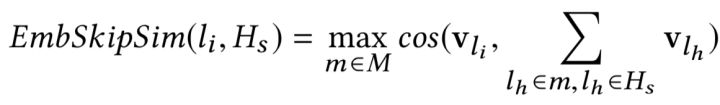
由于Airbnb的场景是推荐房源,所以限制推荐候选房源所属地非常重要。第二点计算跳过的房源相似分,这样相当于一种负反馈的机制,也就说对于那些用户跳过的房源,只要候选房源与他们相似,就不容易被推荐。
房源冷启动问题
冷启动一直是推荐系统很重要问题,这里给了一种冷启动的方法,对于新的listing embedding,因为没有用户行为数据,它利用3个相同类别,相似价格的listing embedding求平均得到。
user-type 和listing-type embedding
仅仅有两个房源之间的相似性还不够,Airbnb希望能直接学习user embedding和listing embedding,然后计算它们的相似性来直接影响排序模型。
首先他们将用户和listing都分别聚类,具有相似特征的user会聚到同一个user-type,而具有相似特征listing聚到相同的listing-type。这里的相似特征指的是基础属性,例如用户最近booked3个房子,用户年龄等等。最终表示成这样的一个id:SF_lg1_dt1_f p1_pp1_nb1_ppn2_ppn3_c2_nr3_l5s3_g5s3,每两个下划线中间表示一个基础特征,所有基础特征相同的user都映射到相同的id。listing的映射也是同理。这样做的目的主要是因为某些user listing的稀疏性,很多用户和listing的行为数较少,比如一个user只有3次点击历史,这样的user直接放进模型中肯定学的不好,但是又不能忽视这样的user,因为这直接决定了embedding 的覆盖量。所以Airbnb想出这种方式来提高覆盖量,listing 的做法也是类似的道理。
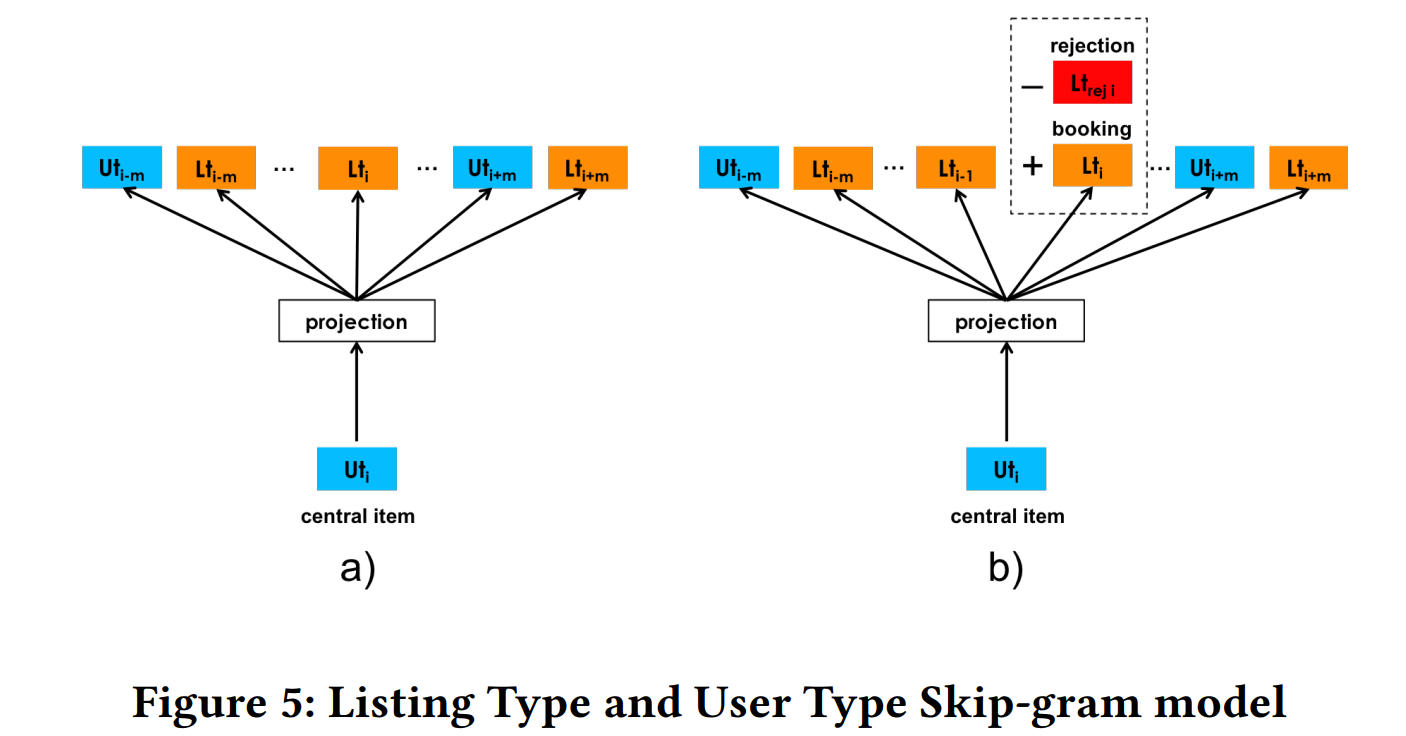
由于Airbnb的场景是为了用户预订房源,所以在学习user embedding的时候只利用用户的booked listing历史。它的优化目标如下:
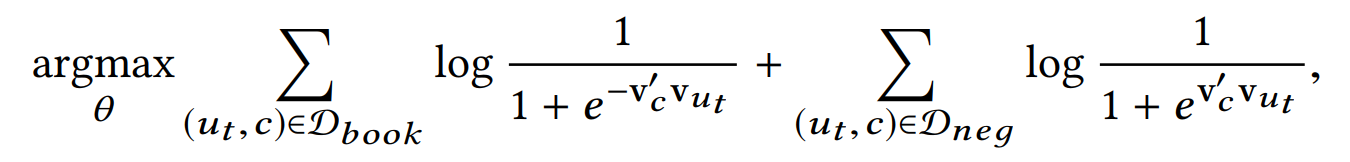
其中$v_{u_t}$表示user-type的embedding,$v_c’$是网络参数,$D_{book}$是用户的booked listing历史集合,$D_{neg}$是负采样的集合。
而对于list-type的embedding通过下面的目标训练:
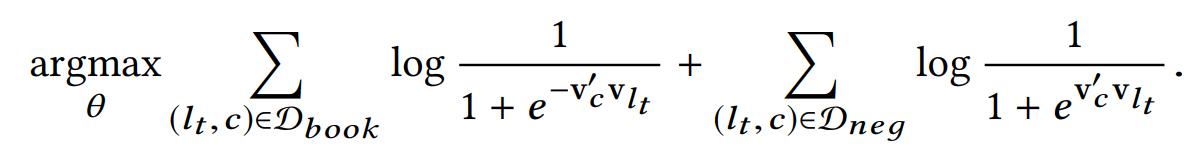
值得注意的时候这里使用的是相同的网络参数$v_c’$,所以通过这种方式能将user-type和listing-type的向量学到同一个空间内。这部分内容可以参考paragraph2vec中的PV-DBOW模型,与之目标相似。
这里还有一个负反馈的方式就是利用了用户rejection的 listing,那这写listing作为负样本。改造之后的目标是:
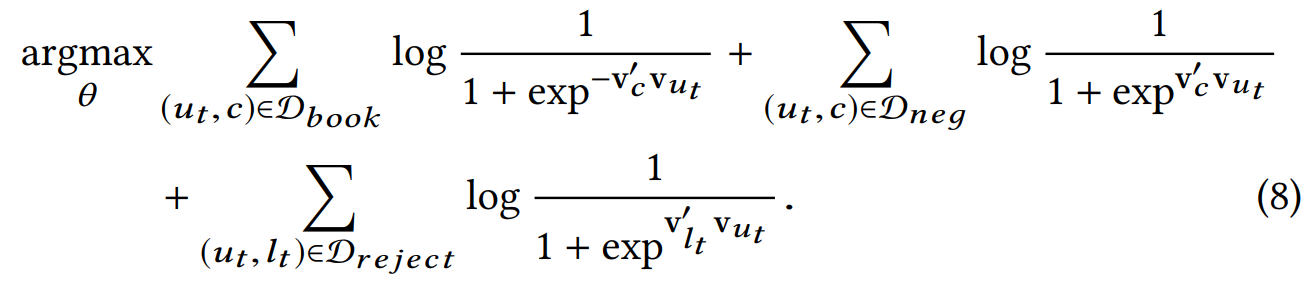
至此,Airbnb这篇论文的几种embedding技术介绍完了,总的来说就是通过skipGram+负采样的训练方式,然后在考虑两点在实际的工程中变形:1.如何构造点击序列,2.如何负采样。Airbnb的经验告诉我们负采样的时候充分利用一些监督信息是很有帮助的。
参考文章